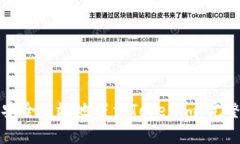
在加密货币交易的世界中,TokenIM作为一款日益流行的钱包和交易工具,为用户提供了便捷的数字货币管理与交易服务...
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和书写,同时也易于机器解析和生成。JSON的格式使用键值对的方式来组织数据,这使它在数据的传输和存储中变得极为受欢迎。使用JSON格式可以很方便地在客户端与服务器之间交换数据,尤其是在Web应用开发中。
主要用途包括:数据传输、配置文件存储(如应用程序配置),以及作为API响应格式等。由于其灵活性和广泛的支持,JSON已经成为了Web服务和RESTful API中数据交换的事实标准。
### Tokenization是什么,为什么在自然语言处理中重要?
Tokenization是将一段文本划分为不同的“tokens”(令牌或词元)的过程。这些tokens可以是单词、词组,甚至单个字符,具体取决于应用的需求。在自然语言处理(NLP)中,Tokenization是文本分析的第一步。
Tokenization的重要性体现在多个方面:首先,它能够显著提高后续分析的准确性,确保模型能够有效理解输入文本。其次,Tokenization可以帮助消除文本中的噪音,比如标点符号和空格,使得数据更加清晰和规范。最后,Tokenization能够简化文本的复杂性,令机器更容易进行后续处理,例如词向量转换、特征提取等。
### 如何使用Python处理JSON文件?Python提供了内置的JSON库,使得操作JSON文件变得简单。可以通过`json`模块进行解析和序列化。以下是一个简单的示例,展示如何读取一个JSON文件并将其转换为Python字典。
import json
# 读取JSON文件
with open('data.json', 'r') as file:
data = json.load(file)
# 输出数据
print(data)
此外,使用Python的Pandas库处理JSON数据也非常方便。Pandas可以将JSON数据直接转换为DataFrame,进行进一步的分析和处理。
例如,可以使用如下代码:
import pandas as pd
# 将JSON数据加载为DataFrame
df = pd.read_json('data.json')
# 输出DataFrame
print(df.head())
Tokenization的实现一般分为几个步骤:首先,选择合适的工具或库,比如NLTK、SpaCy等。然后,载入待处理的文本数据。接下来,根据项目的需求选择Tokenization方式,可能是基于单词、字符或其他特定模式。最后,运行Tokenization过程,记录和分析结果。
例如,在使用Python的NLTK库时,流程可以如下:
import nltk
from nltk.tokenize import word_tokenize
# 下载所需的nltk数据
nltk.download('punkt')
text = "Hello, world! This is a tokenization example."
tokens = word_tokenize(text)
print(tokens)
通过这种方式,可以将输入的句子拆分为独立的词语,为后续处理打下基础。
### 如何结合JSON与Tokenization处理文本?结合JSON数据与Tokenization处理文本的过程通常包括以下几个步骤:首先,从JSON文件中提取文本数据。可以将JSON视为一个包含许多记录的数据库,选择其中包含文本的字段。接下来,对提取的文本数据进行Tokenization。最后,将Tokenization的结果与原始数据结合或进一步应用于分析。
例如,假设有一个JSON文件,里面存储了用户评论,我们想对这些评论进行Tokenization以进行情感分析:
import json
from nltk.tokenize import word_tokenize
# 读取JSON文件
with open('reviews.json', 'r') as file:
data = json.load(file)
for review in data["reviews"]:
tokens = word_tokenize(review["comment"])
print(tokens)
通过这种方式,可以将每条评论转换为一个单词列表,为进一步的分析(如情感分析或主题建模)做好准备。
### JSON文件大小与Tokenization性能的关联是什么?JSON文件的大小通常会影响Tokenization的性能。较大的JSON文件通常包含更多的数据,导致在处理时需要消耗更多的内存和时间。对于Tokenization过程来说,解析和分割较大文本的时间成本显著增高,尤其是在解析的文本中包含丰富的多样性时。
为了改善这一点,可以采取一些措施,比如采用分页加载技术、使用更高效的数据存储格式(如Protocol Buffers),或者优先处理重要数据字段,避免不必要的操作。
例如,在处理非常大的JSON文档时,可以逐行读取并应用Tokenization,尽量避免一次性加载整个文档而导致的性能瓶颈。
### 问题7:常见的Tokenization工具及其优缺点是什么?市场上有许多Tokenization工具,以下是几种常用工具及其优缺点:
1. **NLTK (Natural Language Toolkit)** - **优点**: Python库,功能强大,支持多种Tokenization方式。 - **缺点**: 对新手来说,学习曲线稍陡峭。 2. **SpaCy** - **优点**: 速度快,性能高,用户友好,适合实际应用。 - **缺点**: 功能较为专注于英文本,其他语言支持不如NLTK全面。 3. **Tokenizers (Hugging Face)** - **优点**: 专注于深度学习中的Tokenization,支持各种Transformer模型。 - **缺点**: 主要面向机器学习工程师,普通用户可能觉得复杂。 4. **CoreNLP** - **优点**: 提供全面的NLP功能,支持多种语言和Tokenization方式。 - **缺点**: 需要Java环境,设置较为麻烦。选择合适的Tokenization工具时,开发者需要根据具体的用例和数据特性进行评估。
--- 以上即为关于JSON文件与Tokenization的全面解读,供您在及公众理解方面参考。如需进一步的内容,欢迎继续提问!

在加密货币交易的世界中,TokenIM作为一款日益流行的钱包和交易工具,为用户提供了便捷的数字货币管理与交易服务...
引言 在数字资产管理不断演变的今天,TokenIM 1.0版本应运而生,作为一款去中心化的数字资产管理工具,它承载着越...
IM钱包是什么? IM钱包是一款数字资产管理工具,可以用于存储和管理加密货币、参与区块链项目等。它提供了一个安...
什么是IM钱包? IM钱包是一个数字货币钱包应用程序,旨在为用户提供安全、便捷的数字资产管理和交易功能。它支持...